 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
May 30, 2026Unified multimodal models (UMMs) have emerged as a promising paradigm for general-purpose multimodal intelligence. As they are deployed in real-world applications, effectively updating internal knowledge becomes critical. While knowledge editing has matured for text-only models, it remains unclear whether edits that successfully modify textual outputs also transfer to image generation in UMMs. To study this question, we introduce UniKE, the first benchmark for cross-modality knowledge editing in UMMs, comprising 2,971 edit subjects spanning attribute and relation edits. Using VQA-based visual verification, we reveal a striking modality gap: text-side efficacy can reach approximately 92%, whereas the best overall VQA accuracy under direct image generation is only 18.5%. We further propose Reasoning-augmented Parameter Editing, which explicitly activates edited knowledge before generation and improves overall VQA accuracy for all evaluated model-editor pairs, with gains up to 18.6 percentage points. Mechanistic analysis shows that this gap is associated with partial alignment between edited textual representations and the conditioning pathways for visual generation, where edits sufficient for text outputs may remain too weak or misaligned to steer image synthesis. These findings show that textual knowledge edits do not guarantee reliable cross-modality transfer and motivate modality-aware editing methods. Our code and data are available at https://github.com/gxx27/UniKE.
Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
May 29, 2026We identify a new dimension for enhancing rollout diversity in Group Relative Policy Optimization (GRPO) for LLMs. While GRPO relies on diverse rollouts, prevailing strategies primarily increase diversity by injecting more token-level randomness, which may introduce step-wise noise and lead to incoherent trajectories. We uncover that smaller models within the same model family inherently exhibit higher policy-level diversity, indicated by their superior pass@k relative to larger counterparts as sample counts increase. Unlike token-level noise, this diversity is temporally correlated, preserves logical consistency, and provides structured exploration signals for gradient estimation. We thus propose S2L-PO (Small-to-Large Policy Optimization), a framework that leverages fixed small models as natural explorers to train larger models. To balance exploration and exploitation, we design a progressive annealing strategy that transitions from offline small-model rollouts to the large learner's own sampling. This shift elegantly avoids mid-training performance drops caused by the small model's capacity limits, achieving faster convergence and unlocking a higher performance ceiling. S2L-PO improves accuracy on diverse mathematical reasoning benchmarks (e.g., +8.8% on AIME 24 using a 1.7B explorer to guide the 8B model) while reducing rollout compute.
OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
May 27, 2026Visual outcomes are increasingly central to multimodal large language models, making reliable and fine-grained verification essential for scaling generalist foundation models. In this work, we investigate multimodal meta-verification, which leverages verifier-generated rationales rather than decision-only signals, and explore how to effectively incorporate meta-verification feedback into multimodal verifier training. We identify two key findings. First, symbolic verifier outputs (e.g., bounding boxes) outperform textual explanations as meta-verification rationales, enabling efficient rule-based reinforcement learning rewards while avoiding reliance on model-based rewards from auxiliary judge models. Second, decoupling reinforcement learning objectives for binary judgment and meta-verification substantially outperforms joint reward optimization, due to intrinsic differences in output structure and learning dynamics. Based on these insights, we train OmniVerifier-M1, a generalist visual verifier leveraging symbolic meta-verification and decoupled reinforcement learning. OmniVerifier-M1 provides robust verification and fine-grained error localization, and further enables M1-TTS, a verifier-driven agentic generation system achieving dynamic region-level self-correction. This approach paves the way for more reliable, interpretable, and fine-grained multimodal verification, supporting safer and more controllable foundation model deployment.
EMO: Frustratingly Easy Progressive Training of Extendable MoE
May 14, 2026Sparse Mixture-of-Experts (MoE) models offer a powerful way to scale model size without increasing compute, as per-token FLOPs depend only on k active experts rather than the total pool of E experts. Yet, this asymmetry creates an MoE efficiency paradox in practice: adding more experts balloons memory and communication costs, making actual training inefficient. We argue that this bottleneck arises in part because current MoE training allocates too many experts from the beginning, even though early-stage data may not fully utilize such capacity. Motivated by this, we propose EMO, a simple progressive training framework that treats MoE capacity as expandable memory and grows the expert pool over the course of training. EMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion. Empirical results show that EMO matches the performance of a fixed-expert setup in large-scale experiments while improving wall-clock efficiency. It offers a surprisingly simple yet effective path to scalable MoE training, preserving the benefits of large expert pools while reducing both training time and GPU cost.
From Narrow to Panoramic Vision: Attention-Guided Cold-Start Reshapes Multimodal Reasoning
Mar 04, 2026The cold-start initialization stage plays a pivotal role in training Multimodal Large Reasoning Models (MLRMs), yet its mechanisms remain insufficiently understood. To analyze this stage, we introduce the Visual Attention Score (VAS), an attention-based metric that quantifies how much a model attends to visual tokens. We find that reasoning performance is strongly correlated with VAS (r=0.9616): models with higher VAS achieve substantially stronger multimodal reasoning. Surprisingly, multimodal cold-start fails to elevate VAS, resulting in attention distributions close to the base model, whereas text-only cold-start leads to a clear increase. We term this counter-intuitive phenomenon Lazy Attention Localization. To validate its causal role, we design training-free interventions that directly modulate attention allocation during inference, performance gains of 1$-$2% without any retraining. Building on these insights, we further propose Attention-Guided Visual Anchoring and Reflection (AVAR), a comprehensive cold-start framework that integrates visual-anchored data synthesis, attention-guided objectives, and visual-anchored reward shaping. Applied to Qwen2.5-VL-7B, AVAR achieves an average gain of 7.0% across 7 multimodal reasoning benchmarks. Ablation studies further confirm that each component of AVAR contributes step-wise to the overall gains. The code, data, and models are available at https://github.com/lrlbbzl/Qwen-AVAR.
Asymmetric Idiosyncrasies in Multimodal Models
Feb 26, 2026In this work, we study idiosyncrasies in the caption models and their downstream impact on text-to-image models. We design a systematic analysis: given either a generated caption or the corresponding image, we train neural networks to predict the originating caption model. Our results show that text classification yields very high accuracy (99.70\%), indicating that captioning models embed distinctive stylistic signatures. In contrast, these signatures largely disappear in the generated images, with classification accuracy dropping to at most 50\% even for the state-of-the-art Flux model. To better understand this cross-modal discrepancy, we further analyze the data and find that the generated images fail to preserve key variations present in captions, such as differences in the level of detail, emphasis on color and texture, and the distribution of objects within a scene. Overall, our classification-based framework provides a novel methodology for quantifying both the stylistic idiosyncrasies of caption models and the prompt-following ability of text-to-image systems.
UReason: Benchmarking the Reasoning Paradox in Unified Multimodal Models
Feb 09, 2026To elicit capabilities for addressing complex and implicit visual requirements, recent unified multimodal models increasingly adopt chain-of-thought reasoning to guide image generation. However, the actual effect of reasoning on visual synthesis remains unclear. We present UReason, a diagnostic benchmark for reasoning-driven image generation that evaluates whether reasoning can be faithfully executed in pixels. UReason contains 2,000 instances across five task families: Code, Arithmetic, Spatial, Attribute, and Text reasoning. To isolate the role of reasoning traces, we introduce an evaluation framework comparing direct generation, reasoning-guided generation, and de-contextualized generation which conditions only on the refined prompt. Across eight open-source unified models, we observe a consistent Reasoning Paradox: Reasoning traces generally improve performance over direct generation, yet retaining intermediate thoughts as conditioning context often hinders visual synthesis, and conditioning only on the refined prompt yields substantial gains. Our analysis suggests that the bottleneck lies in contextual interference rather than insufficient reasoning capacity. UReason provides a principled testbed for studying reasoning in unified models and motivates future methods that effectively integrate reasoning for visual generation while mitigating interference.
From Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
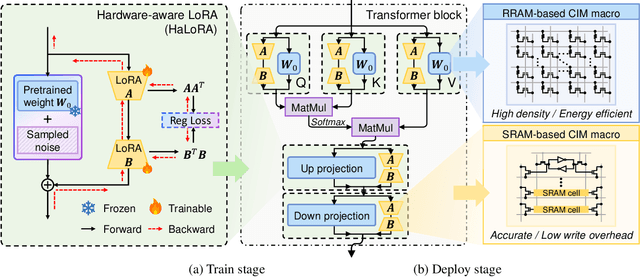
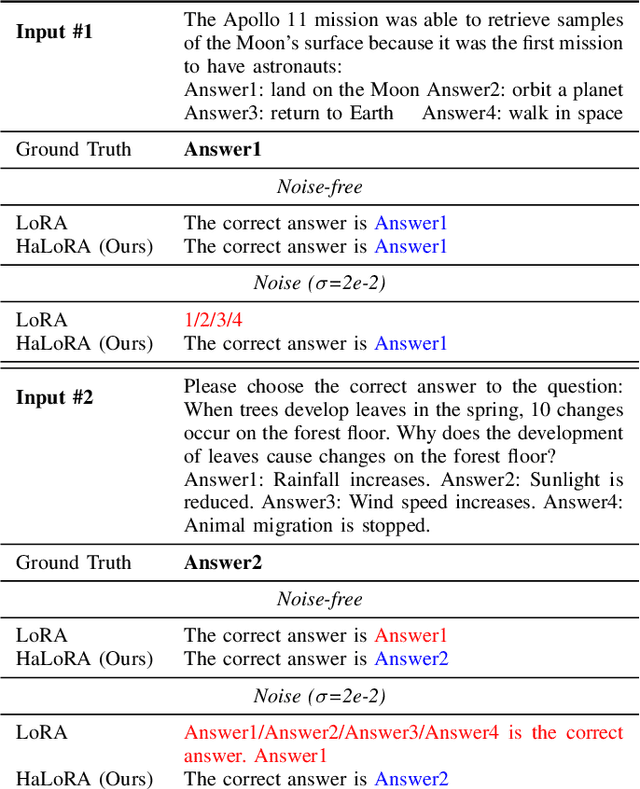
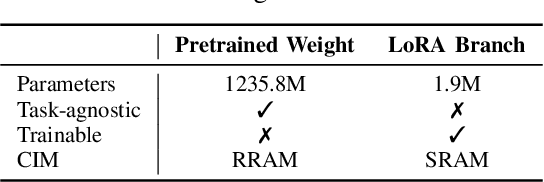
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
LLM2: Let Large Language Models Harness System 2 Reasoning
Dec 29, 2024



Large language models (LLMs) have exhibited impressive capabilities across a myriad of tasks, yet they occasionally yield undesirable outputs. We posit that these limitations are rooted in the foundational autoregressive architecture of LLMs, which inherently lacks mechanisms for differentiating between desirable and undesirable results. Drawing inspiration from the dual-process theory of human cognition, we introduce LLM2, a novel framework that combines an LLM (System 1) with a process-based verifier (System 2). Within LLM2, the LLM is responsible for generating plausible candidates, while the verifier provides timely process-based feedback to distinguish desirable and undesirable outputs. The verifier is trained with a pairwise comparison loss on synthetic process-supervision data generated through our token quality exploration strategy. Empirical results on mathematical reasoning benchmarks substantiate the efficacy of LLM2, exemplified by an accuracy enhancement from 50.3 to 57.8 (+7.5) for Llama3-1B on GSM8K. Furthermore, when combined with self-consistency, LLM2 achieves additional improvements, boosting major@20 accuracy from 56.2 to 70.2 (+14.0).